Distinguishing pairs of classes on MNIST and Fashion-MNIST with just one pixel
🏷️ tags: Data Python Statistics
Fashion-MNIST is a machine learning benchmarking dataset created to replace MNIST, as MNIST is relatively easy to predict and therefore is not enough of a challenge to test different machine learning models.
One of the arguments mentioned by the creators at Zalando Research is that most pairs can be classified with just one pixel.
MNIST is too easy. Convolutional nets can achieve 99.7% on MNIST. Classic machine learning algorithms can also achieve 97% easily. Check out our side-by-side benchmark for Fashion-MNIST vs. MNIST, and read “Most pairs of MNIST digits can be distinguished pretty well by just one pixel.”
I was curious to see in which measure this is actually possible and how different Fashion-MNIST is by comparison. Here is what I discovered.
Datasets characteristics
Fashion-MNIST is meant as a drop-in replacement for MNIST and is based on clothing items pictures by the German online retailer Zalando.
- Both datasets have the same size: 50 000 images in the training set and 10 000 in the validation set.
- Both datasets have 10 classes: the ten digits 0 to 9 for MNIST, and ten kinds of clothing items for Fashion-MNIST.
- Both datasets are composed of 28 by 28 greyscale images. Each pixel is a number 0 from 255 representing the greyscale intensity.
MNIST Fashion-MNIST 0 T-shirt/top 1 Trouser 2 Pullover 3 Dress 4 Coat 5 Sandal 6 Shirt 7 Sneaker 8 Bag 9 Ankle boot
Differences in the average pixel densities
The link by Zalando Research goes to an R script by David Robinson which generates a chart later included in a blog post in 2018. It compares the difference in average pixel density for each pair of images. Intuitively the bigger the difference (the more intense the colours), the easier it will be to distinguish the classes. By repeating the same procedure for both MNIST and Fashion-MNIST we get this.
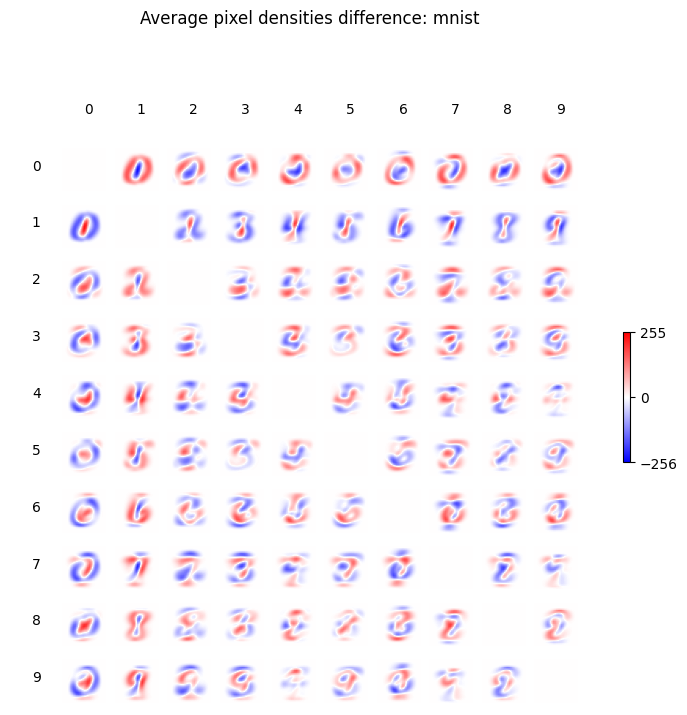
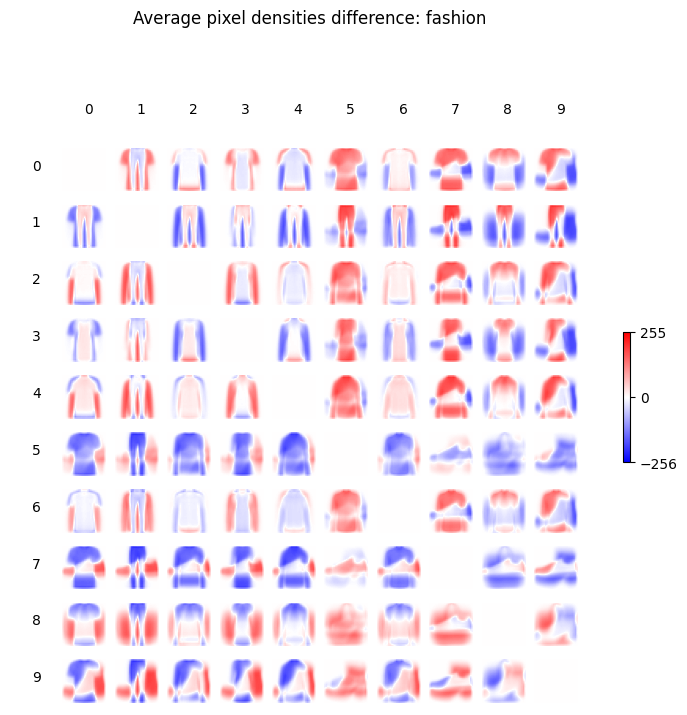
This visualization hints which pairs are easier to distinguish when picking just one pixel to look at, like 0 vs 1 in MNIST, as well 1-trouser vs 7-sneaker in Fashion-MNIST. By considering a pixel where the colour is more intense, one can realistically identify a solid threshold between the two classes. Other pairs will probably be tougher, like 4 vs 9 in MNIST or 2-pullover vs 6-shirt in Fashion-MNIST.
Machine learning with one pixel
I tried to pick “the best” pixel for each pair with logistic regression. By “the best” I mean the one with the highest in-sample accuracy, computed through the following algorithm:
- For each pair of classes and for each pixel, I ran the same class vs class logistic regression.
- For each pair of classes I would only store the weights and the position of the pixel with the best in sample accuracy.
- I then tested the model on the validation dataset for that pixel and weights, the following charts shows the corresponding out of sample accuracy. The scale starts from 0.5, as this would be the baseline by picking the class at random.
![]()
![]()
We can see is the following:
- On both datasets the prediction with one pixel chosen appropriately is better than chance for all pairs.
- The best case scenarios have nearly perfect accuracy on both datasets (0.99): 0 vs 1 on MNIST and 1-trouser vs 7-sneaker on Fashion-MNIST.
- The worst-case scenario is significantly worse on Fashion-MNIST: 3 vs 5 on MNIST (0.76) compared to 4-coat vs 6-shirt (0.67).
- Some classes of Fashion-MNIST perform very well:
- 5-sandal, 7-sneaker, 8-bag, 9-ankle-boot have at least 0.95 accuracy against at least six other classes.
- That is less often the case in MNIST: only three pairs have at least 0.95 accuracy: 0 vs 1, 0 vs 4, 1 vs 8.
- The accuracy is at least 0.9 for 33 pairs of Fashion-MNIST and only 15 pairs of MNIST.
Conclusions
The claim by Zalando Research that “most pairs of MNIST digits can be distinguished pretty well by just one pixel” while correct does not seem to be informative, as this is also the case for Fashion-MNIST. If anything, it is even “more correct” for Fashion-MNIST, as 0.9 accuracy can be achieved in more than twice as many pairs than MNIST.
Yet for practical purposes this finding doesn’t matter: the point of Fashion-MNIST is to be used as replacement for a regression over all classes. As the benchmarks by Zalando Research show, typical machine learning algorithms tend to perform worse as wished. This confirms that the dataset is indeed more complex and more difficult to predict. The interesting insight for me was to see how a property that intuitively should have not been shared by Fashion-MNIST actually ended up being even more pronounced when checked numerically.