AI safety matters because humanity matters
🏷️ tags: AI
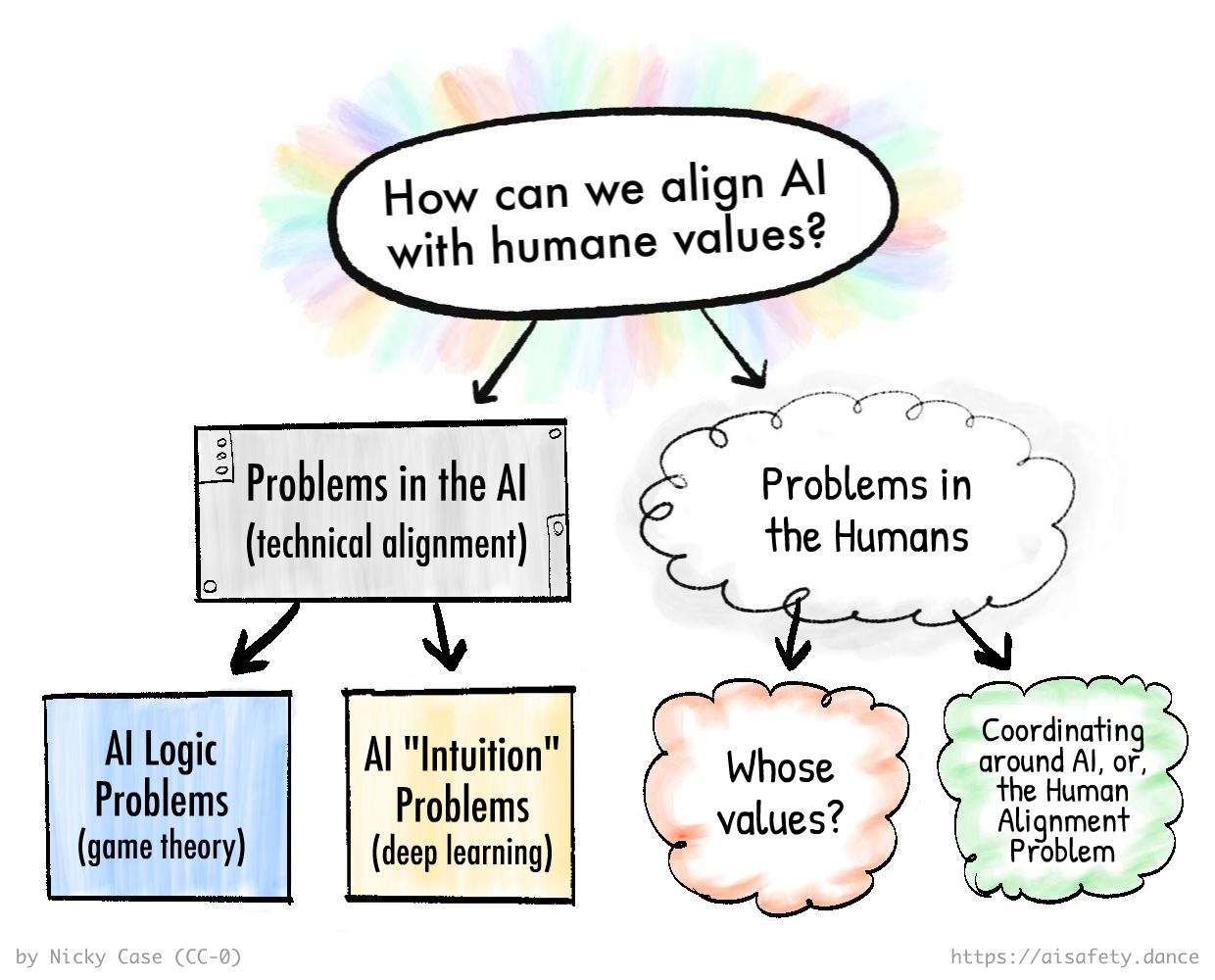
Nicky Case recently released the final part of her AI safety series. What I appreciate most about the series is how she clearly frames AI safety as both a technological and a human problem.
AI Safety for Fleshy Humans - part 3
While complex, the technological aspect is perhaps the easier one to grasp. Large language models (LLMs) are already misaligned in ways previously theorized for artificial general intelligence (AGI)1. For example, there is experimental evidence that LLMs may pretend to be safe during training only to act maliciously in production2. Even if AGI is unachievable, LLMs have made AI safety a pressing concern today3.
The human problem is more insidious than the technological one. Even with the technology to perfectly align AI, what happens if humanity can’t agree on what it should do? For example AI is already deployed in military applications, where reasonable people can hold vastly different ethical views.
My main takeaway from the series is a stronger awareness of what to prioritize. Any decision about technology must start with its potential benefit to humanity. In the realm of AI tools, I refuse to abandon discussions on AI policy in favour of unchecked technological progress. If political and market incentives aren’t aligned in the right direction, humanity has a shared responsibility to guide them accordingly.
Footnotes
-
A great book about the AI control problem is Superintelligence by Nick Bostrom (2014) ↩
-
This is known as deceptive alignment, also informally called volkswagening. It is described in the paper Alignment faking in large language models (arXiv:2412.14093). One of the authors discussed it in this video: AI Will Try to Cheat & Escape (aka Rob Miles was Right!) - Computerphile (YouTube). ↩
-
For a candid perspective on the shift in AI research, check out the video AI Ruined My Year by Robert Miles (YouTube). ↩